
UnicodeDecodeError: ‘utf-8’ 编解码器无法解码位置字节:无效的连续字节
UnicodeDecodeError: ‘utf-8’ codec can’t decode byte in position: invalid continuation byte
Python“UnicodeDecodeError: ‘utf-8’ codec can’t decode byte in position: invalid continuation byte” 当我们在解码字节对象时指定不正确的编码时发生。
要解决该错误,请指定正确的编码,例如latin-1.
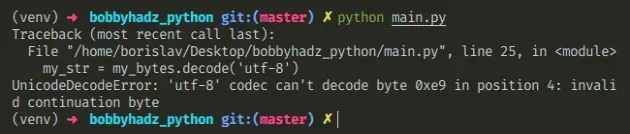
下面是错误如何发生的示例。
my_bytes = 'one é two'.encode('latin-1') # ⛔️ UnicodeDecodeError: 'utf-8' codec can't decode byte 0xe9 in position 4: invalid continuation byte my_str = my_bytes.decode('utf-8')
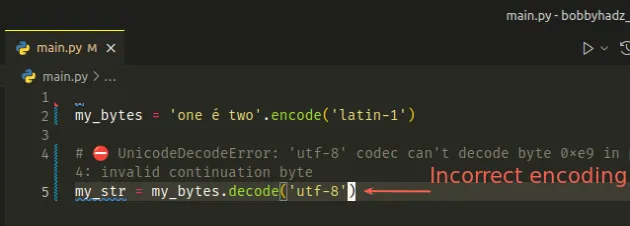
请注意,字符串已使用latin-1编码编码为字节。
如果我们尝试使用不同的编码(例如 )解码字节对象utf-8,则会引发错误。
两种编码不同,产生不同的结果。
my_str = 'one é two' print(my_str.encode('latin-1')) # 👉️ b'one \xe9 two' print(my_str.encode('utf-8')) # 👉️ b'one \xc3\xa9 two'
string编码是将 a 转换为对象的过程,解码是将对象转换为 a 的过程。 bytes bytesstring解码字节对象时,我们必须使用与将字符串编码为字节对象相同的编码。
设置编码为latin-1解决错误
在示例中,我们可以将编码设置为latin-1.
my_bytes = 'one é two'.encode('latin-1') my_str = my_bytes.decode('latin-1') print(my_str) # 👉️ "one é two"
用于将字符串转换为字节对象的编码与用于将字节对象转换为字符串的编码相匹配,因此一切都按预期进行。
latin -1编码由来自拉丁文字的 191 个字符组成,在美洲、西欧、大洋洲和非洲广泛使用。
latin-1从文件读取时设置编码
如果您在使用 读取文件时遇到错误pandas,请尝试将编码设置为latin-1或在对read_csvISO-8859-1方法的调用中
。
import pandas as pd # 👇️ set encoding to latin-1 df = pd.read_csv('employees.csv', sep='|', encoding='latin-1') # first_name last_name # 0 Alice Smith # 1 Bobby Hadz print(df)
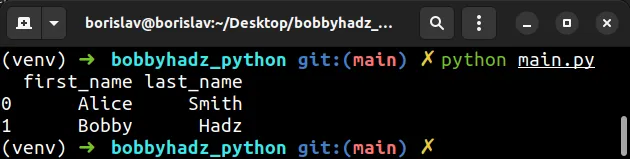
代码示例假定employees.csv在与 Python 脚本相同的目录中有一个文件。
first_name|last_name Alice|Smith Bobby|Hadz
如果使用本机open() 函数,您可以尝试做同样的事情
。
import csv with open('employees.csv', newline='', encoding='latin-1') as csvfile: csv_reader = list(csv.reader(csvfile, delimiter='|')) # [['first_name', 'last_name'], ['Alice', 'Smith'], ['Bobby', 'Hadz']] print(csv_reader)
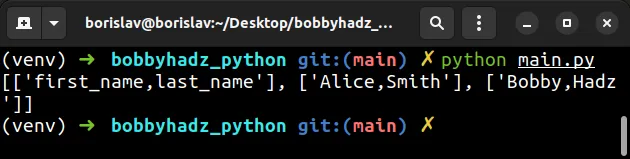
如果您使用open()不带with 语句的本机函数,则可以使用相同的方法。
import csv csv_file = open('employees.csv', newline='', encoding='latin-1') csv_reader = list(csv.reader(csv_file, delimiter='|')) # [['first_name', 'last_name'], ['Alice', 'Smith'], ['Bobby', 'Hadz']] print(csv_reader) csv_file.close()
如果latin-1编码没有产生清晰的结果,请尝试将编码设置为ISO-8859-1.
import pandas as pd # 👇️ set encoding to ISO-8859-1 df = pd.read_csv('employees.csv', sep='|', encoding='ISO-8859-1') # first_name last_name # 0 Alice Smith # 1 Bobby Hadz print(df)
编码ISO-8859-1为 256 个可能的字节值中的每一个定义一个字符,因此不会引发错误。
编码也可以传递给本机open()函数。
import csv csv_file = open('employees.csv', newline='', encoding='ISO-8859-1') csv_reader = list(csv.reader(csv_file, delimiter='|')) # [['first_name', 'last_name'], ['Alice', 'Smith'], ['Bobby', 'Hadz']] print(csv_reader) csv_file.close()
将errors关键字参数设置为ignore
如果错误仍然存在,您可以将
errors 关键字参数设置
为ignore以忽略无法解码的字符。
请注意,忽略无法解码的字符会导致数据丢失。
import csv # 👇️ set errors to ignore with open('employees.csv', newline='', encoding='utf-8', errors='ignore') as csvfile: csv_reader = list(csv.reader(csvfile, delimiter='|')) # [['first_name', 'last_name'], ['Alice', 'Smith'], ['Bobby', 'Hadz']] print(csv_reader)
errors使用设置为的不正确编码打开文件ignore不会引发UnicodeDecodeError.
rb如果您必须从中读取文件,请确保您没有以(读取二进制)模式打开文件。
解码字节时设置errors参数ignore
您还可以在方法调用中将errors参数设置为
。ignoredecode()
my_bytes = 'one é two'.encode('latin-1') my_str = my_bytes.decode('utf-8', errors='ignore') print(my_str) # 👉️ one two
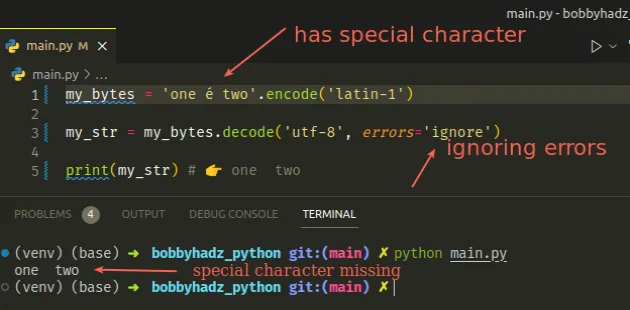
我们设置了不正确的编码但没有收到错误,因为errors
关键字参数设置为ignore.
但是请注意,忽略无法解码的字符可能会导致数据丢失。
以二进制方式打开文件
如果您不需要与文件内容进行交互,您可以在不解码的情况下以二进制模式打开它。
with open('example.txt', 'rb') as f: lines = f.readlines() # ✅ [b'one \xc3\xa9 two'] print(lines)
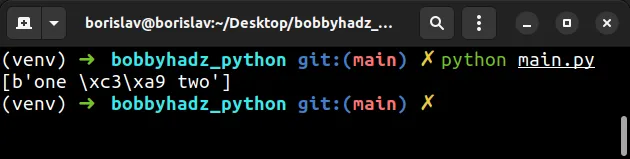
该代码示例假定您example.txt在脚本所在的目录中有一个文件main.py。
one é two
rb我们以二进制模式(使用模式)打开文件,因此lines列表包含字节对象。
encoding以二进制模式打开文件时不应指定。
如果读取或写入 PDF 文件,请使用rbor编码wb
请注意,如果您尝试读取或写入 PDF 文件,则必须使用rb(读取二进制)或wb(写入二进制)模式,因为 PDF 文件是以字节形式存储的。
with open('example.pdf', 'rb') as file1: my_bytes = file1.read() # 👇️ specify correct encoding print(my_bytes.decode('latin-1'))
代码示例假定有一个example.pdf文件位于与您的脚本相同的目录中main.py。
尝试使用 ‘ISO-8859-1’ 编码
如果错误仍然存在,请尝试使用ISO-8859-1编码。
my_bytes = 'one é two'.encode('latin-1') my_str = my_bytes.decode('ISO-8859-1') print(my_str) # 👉️ one é two
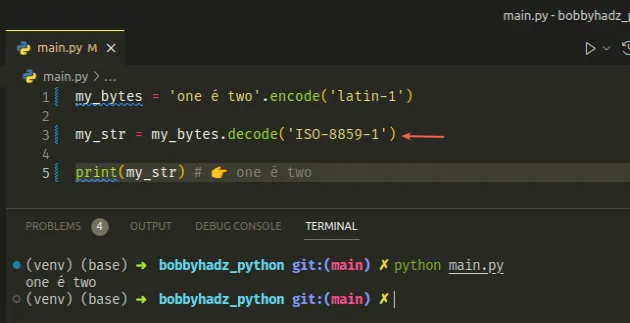
当编码设置为ISO-8859-1时,您不会收到错误消息
,但是,您可能会收到难以辨认的结果。
编码ISO-8859-1为 256 个可能的字节值中的每一个定义一个字符,因此不会引发错误。
这是从文件读取时使用编码的示例。
with open('example.txt', 'r', encoding='ISO-8859-1') as f: lines = f.readlines() print(lines)
试图找到文件的编码
您可以尝试使用命令来弄清楚文件的编码是什么file
。
该命令在 macOS 和 Linux 上可用,但如果安装了 git 和 Git Bash,也可以在 Windows 上使用。
如果在 Windows 上,请确保在 Git Bash 中运行该命令。
在包含该文件的目录中打开 shell,然后运行以下命令。
file *
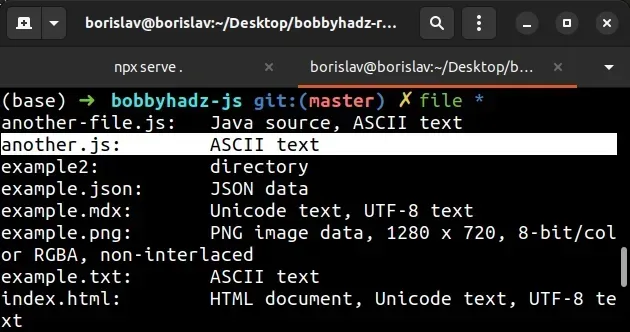
屏幕截图显示该文件使用ASCII编码。
这是您在打开文件时应指定的编码。
with open('example.txt', 'r', encoding='ascii') as f: lines = f.readlines() print(lines)
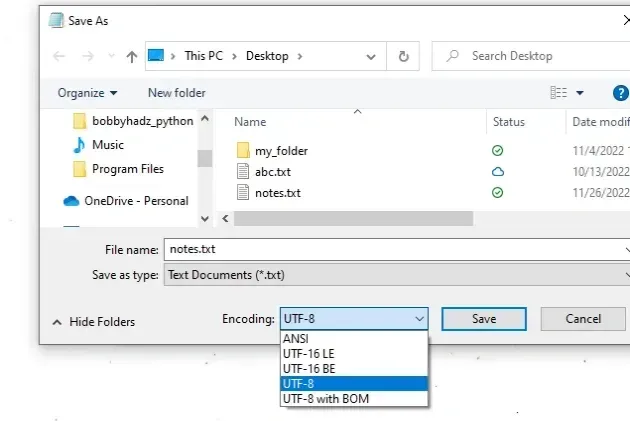
如果您使用的是 Windows,您还可以:
- 在记事本的基本版本中打开文件。
- 单击“另存为”。
- 查看“保存”按钮旁边的所选编码。
使用chardet模块检测文件的编码
如果找不到文件的编码,请尝试安装和使用
chardet Python 模块。
pip install chardet # 👇️ or pip3 pip3 install chardet
现在按如下方式运行chardetect命令。
chardetect your_file
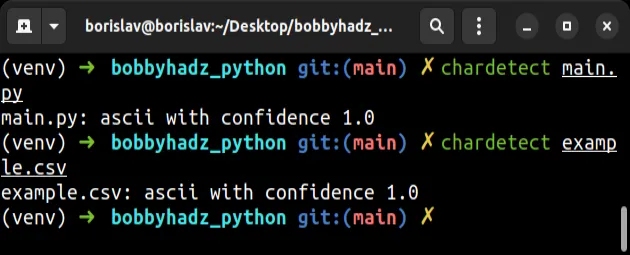
该包将尝试检测指定文件的编码。
然后您可以尝试在打开文件时使用编码。
with open('example.txt', 'r', encoding='your_encoding') as f: lines = f.readlines() print(lines)
您也可以尝试以二进制方式打开文件,并使用chardet包来检测文件的编码。
import chardet with open('example.txt', 'rb') as f: print(chardet.detect(f.read()))
我们使用rb(读取二进制)模式并将文件的输出提供给该
chardet.detect()方法。
您通过调用该方法获得的编码是您在以阅读模式打开文件时应该尝试的编码。
以UTF-8编码保存文件
您可以尝试的另一件事是使用编码保存文件UTF-8。
你可以:
- 单击顶部菜单中的“文件” 。
- 单击“另存为”。
- 将编码设置为
UTF-8并保存文件。
错误是如何发生的
string编码是将 a 转换为对象的过程,解码是将对象转换为 a 的bytes过程。bytesstring
解码字节对象时,我们必须使用与将字符串编码为字节对象相同的编码。
下面是一个示例,显示使用不同的编码将字符串编码为字节而不是用于解码字节对象的编码如何导致错误。
my_text = 'one æåäãé two' my_binary_data = my_text.encode('latin-1') # ⛔️ UnicodeDecodeError: 'utf-8' codec can't decode byte 0xe6 in position 4: invalid continuation byte my_text_again = my_binary_data.decode('utf-8')
latin-1我们可以通过使用编码来解码字节对象来解决错误。
my_text = 'one æåäãé two' my_binary_data = my_text.encode('latin-1') my_text_again = my_binary_data.decode('latin-1') print(my_text_again) # "one æåäãé two"
常见错误原因
“UnicodeDecodeError: ‘utf-8’ codec can’t decode byte in position: invalid continuation byte”错误通常在以下情况下引起:
- 解码字节对象时使用了不正确的编码。
rb我们以(读取二进制)或(写入二进制)打开文件wb并尝试从中读取或写入。
额外资源
您可以通过查看以下教程来了解有关相关主题的更多信息: