
目录
AttributeError: ‘DataFrame’ object has no attribute ‘ix’
注意:如果出现错误“AttributeError: DataFrame object has no attribute as_matrix”,请单击第二个副标题。
AttributeError: ‘DataFrame’ 对象没有属性 ‘ix’
“AttributeError: ‘DataFrame’ object has no attribute ‘ix’” 发生是因为ix索引器已被弃用和删除。
要解决该错误,请使用loc索引器进行基于标签的索引,使用
iloc索引器进行基于位置的索引。
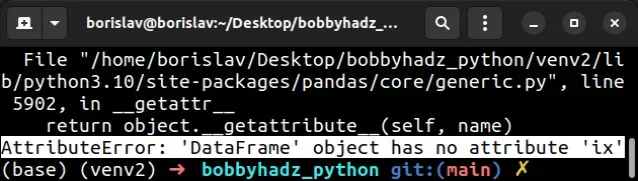
return object.__getattribute__(self, name) AttributeError: 'DataFrame' object has no attribute 'ix'
使用loc索引器进行基于标签的索引
下面是一个使用loc索引器的示例
,它用于基于标签的索引。
import pandas as pd df = pd.DataFrame([[1, 2], [4, 5], [7, 8]], index=['cobra', 'viper', 'sidewinder'], columns=['max_speed', 'shield']) print('=' * 30) # 👇️ single label print(df.loc['viper']) print('=' * 30) # 👇️ list of labels print(df.loc[['viper', 'sidewinder']]) print('=' * 30) # 👇️ slice with labels for row and single label for column print(df.loc['cobra':'viper', 'max_speed']) print('=' * 30) print(df.loc[:, 'max_speed'])
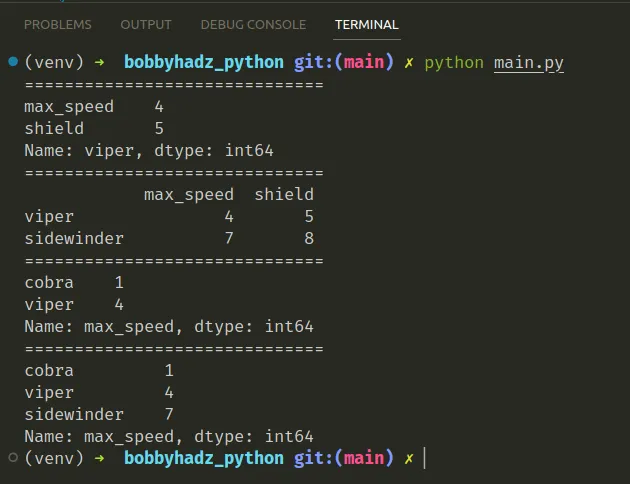
索引loc器允许我们通过标签或布尔数组访问一组行和列。
使用iloc索引器进行基于位置的索引
下面是使用iloc索引器的示例
,它用于基于位置(基于整数)的索引。
import pandas as pd df = pd.DataFrame([[1, 2], [4, 5], [7, 8]], index=['cobra', 'viper', 'sidewinder'], columns=['max_speed', 'shield']) print(df) print('=' * 30) # 👇️ with scalar integer print(df.iloc[0]) print('=' * 30) # 👇️ with list of integer print(df.iloc[[0]]) print(df.iloc[[0, 1]]) print('=' * 30) # 👇️ with a slice object print(df.iloc[:3]) print('=' * 30) print(df.iloc[:, 1])
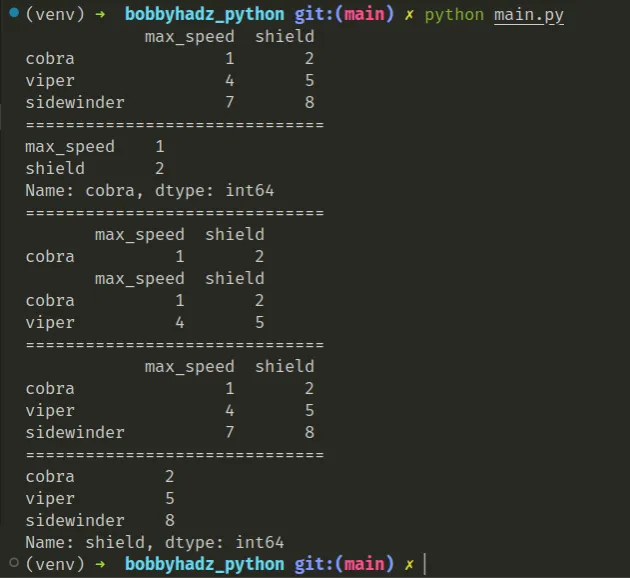
简而言之,
loc
用于按标签选择行和列。
iloc
用于按整数位置选择行和列。
ix已删除的索引器首先执行基于标签的索引,如果失败,则回退到基于整数的索引。
换句话说,ix索引器以前用于混合整数和基于标签的访问。
ix您可以在
文档的这一部分阅读已弃用的索引器。

| 姓名 | 描述 |
|---|---|
| 位置 | 用于按标签选择行和列 |
| 伊洛克 | 用于按整数位置选择行和列 |
| 九 | 已被删除,以前用于混合整数和基于标签的访问。 |
使用loc和iloc索引器通常更直观,因为它使我们的代码更明确。
当轴基于整数时,仅支持基于标签的访问,而不支持基于位置的访问。
在这些情况下,使用locor更直观iloc。
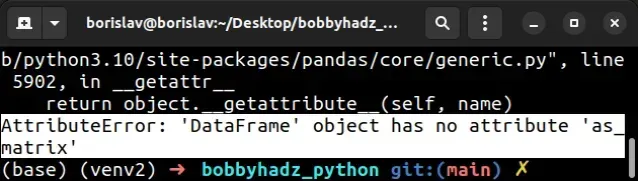
AttributeError: DataFrame 对象没有属性 as_matrix
出现“AttributeError: DataFrame object has no attribute as_matrix”是因为该as_matrix()方法自 NumPy 版本以来已被弃用
0.23.0。
要解决该错误,请改用该to_numpy()方法。
正如
文档
所述,该as_matrix()方法自 version 以来已被弃用和删除
0.23.0。
要解决该错误,请改用该to_numpy方法。
import pandas as pd df = pd.DataFrame({'A': [1, 2], 'B': [3, 4]}) # ✅ Convert DataFrame to a NumPy array arr = df.to_numpy() # [[1 3] # [2 4]] print(arr) print(type(arr)) # 👉️ <class 'numpy.ndarray'> # ---------------------------------------- # ✅ Convert a subset of columns to a NumPy array arr = df[['A']].to_numpy() # [[1] # [2]] print(arr) print(type(arr)) # 👉️ <class 'numpy.ndarray'>
to_numpy
方法将 DataFrame 转换为 NumPy 数组。
to_numpy()方法。该to_numpy方法采用dtype和copy作为可选参数。
如果DataFrame存储异构数据,则使用最低通用类型。
import pandas as pd df = pd.DataFrame({'A': [1, 2], 'B': [3.1, 4.2]}) # ✅ Convert DataFrame to a NumPy array arr = df.to_numpy() # [[1. 3.1] # [2. 4.2]] print(arr) print(type(arr)) # 👉️ <class 'numpy.ndarray'> # ---------------------------------------- # ✅ Convert a subset of columns to a NumPy array arr = df[['A']].to_numpy() # [[1] # [2]] print(arr) print(type(arr)) # 👉️ <class 'numpy.ndarray'>
如果得到“AttributeError: ‘Series’ object has no attribute ‘as_matrix’”,解决方法是一样的。您必须改用
Series.to_numpy
方法。
import pandas as pd ser = pd.Series(['a', 'b', 'c']) arr = ser.to_numpy() print(arr) # 👉️ ['a' 'b' 'c'] print(type(arr)) # 👉️ <class 'numpy.ndarray'>
该Series.to_numpy方法返回一个ndarray代表Series.
额外资源
您可以通过查看以下教程来了解有关相关主题的更多信息: