
# UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0x92 in position
UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0x92 in position
The Python “UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0x92 in
position: invalid start byte” occurs when we specify an incorrect encoding when
decoding a bytes object.
To solve the error, specify the correct encoding, e.g. cp1252.

Here is an example of how the error occurs.
my_bytes = 'abc ’ def'.encode('cp1252') # ⛔️ UnicodeDecodeError: 'utf-8' codec can't decode byte 0x92 in position 4: invalid start byte my_str = my_bytes.decode('utf-8')
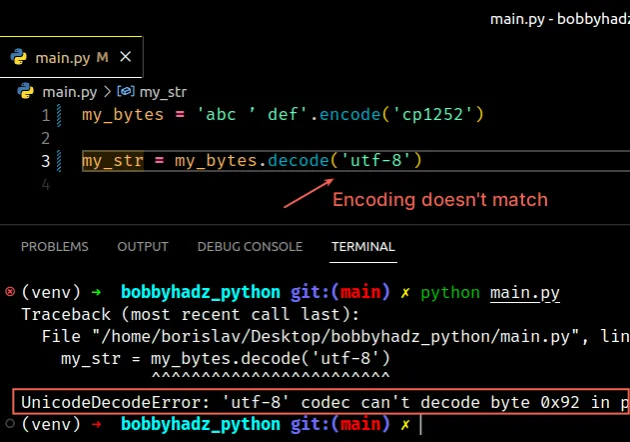
Notice that the string was encoded using the cp1252 encoding and then we tried
to decode the bytes object using the utf-8 encoding.
The two encodings don’t match.
The 0x92 byte can be decoded using the cp1252 encoding.
string to a bytes object and decoding is the process of converting a bytes object to a string.# Use the same encoding that was used to encode the string to bytes
When decoding a bytes object, we have to use the same encoding that was used to
encode the string to a bytes object.
In the example, we can set the encoding to cp1252.
my_bytes = 'abc ’ def'.encode('cp1252') my_str = my_bytes.decode('cp1252') print(my_str) # 👉️ "abc ’ def"
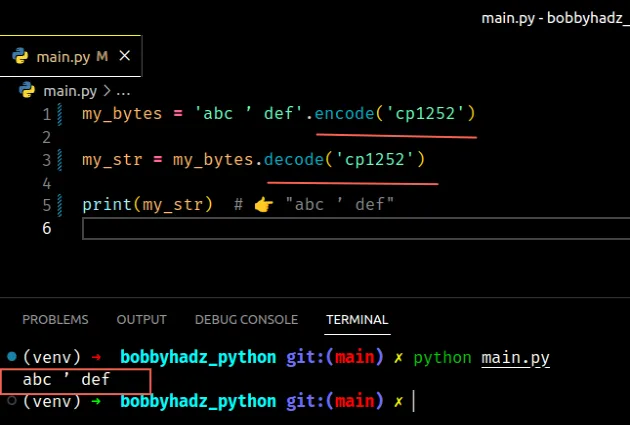
Windows-1252 or cp1252 is a
single-byte character encoding of the Latin alphabet.
If that doesn’t work, try using the latin-1 encoding and see if the data is
legible.
my_bytes = 'abc ’ def'.encode('cp1252') my_str = my_bytes.decode('latin-1') print(my_str) # 👉️ "abc def"
Notice that the character that cannot be decoded got stripped when using the
latin-1 encoding.
You can also try using the mac_roman encoding if the file or string was
created on a macOS machine.
my_bytes = 'abc ’ def'.encode('cp1252') my_str = my_bytes.decode('mac_roman') print(my_str) # 👉️ "abc í def"
# Specify the correct encoding when reading from a file using pandas
If you got the error when reading from a file using
pandas, try setting the encoding to
cp1252 or latin-1.
import pandas as pd # 👇️ set encoding to cp1252 df = pd.read_csv('employees.csv', sep='|', encoding='cp1252') print(df)
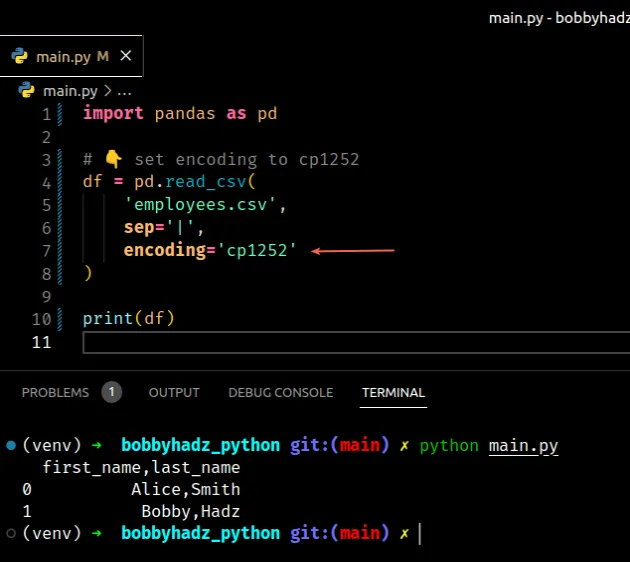
The code sample assumes that you have an employees.csv file in the same
directory as your Python script.
first_name,last_name Alice,Smith Bobby,Hadz
You can try doing the same if using the native
open() function.
import csv with open('employees.csv', newline='', encoding='cp1252') as csvfile: csv_reader = list(csv.reader(csvfile, delimiter='|')) print(csv_reader)
# Setting the errors keyword argument to ignore
如果错误仍然存在,您可以将
errors 的关键字参数设置
为ignore以忽略无法解码的字符。
请注意,忽略无法解码的字符会导致数据丢失。
import csv # 👇️ set errors to ignore with open('employees.csv', newline='', encoding='utf-8', errors='ignore') as csvfile: csv_reader = list(csv.reader(csvfile, delimiter='|')) print(csv_reader)
errors使用设置为的不正确编码打开文件不会引发. ignoreUnicodeDecodeErrorrb如果您必须从中读取文件,请确保您没有以(读取二进制)模式打开文件。
如果不需要与之交互,则以二进制模式打开文件
如果您不需要与文件内容进行交互,您可以在不解码的情况下以二进制模式打开它。
with open('example.txt', 'rb') as f: data = f.read() print(data)
我们以二进制模式(使用模式)打开文件rb,因此该data变量包含一个字节对象。
以二进制模式打开文件时不应
指定编码。
如果您需要将文件上传到远程服务器并且不需要对其进行解码,则可以使用这种方法。
错误是如何发生的
string编码是将 a 转换为对象的过程,解码是将对象转换为 a 的bytes过程。bytesstring
解码字节对象时,我们必须使用与将字符串编码为字节对象相同的编码。
下面的示例展示了如何使用与解码 bytes 对象不同的编码将字符串编码为字节,从而导致错误。
my_text = 'a ’ b' my_binary_data = my_text.encode('cp1252') # ⛔️ UnicodeDecodeError: 'utf-8' codec can't decode byte 0x92 in position 2: invalid start byte my_text_again = my_binary_data.decode('utf-8')
cp1252我们可以通过使用编码来解码字节对象来解决错误。
my_text = 'a ’ b' my_binary_data = my_text.encode('cp1252') my_text_again = my_binary_data.decode('cp1252') print(my_text_again) # 👉️ "a ’ b"