
UnicodeDecodeError: ‘utf-8’ 编解码器无法解码位置 0 中的字节 0xff
UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xff in position 0
Python“UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xff in position 0: invalid start byte” 当我们在解码字节对象时指定不正确的编码时发生。
要解决该错误,请指定正确的编码,例如或以二进制模式(或)utf-16打开文件。rbwb
下面是错误如何发生的示例。
my_bytes = 'hello ÿ'.encode('utf-16') # ⛔️ UnicodeDecodeError: 'utf-8' codec can't decode byte 0xff in position 0: invalid start byte my_str = my_bytes.decode('utf-8')
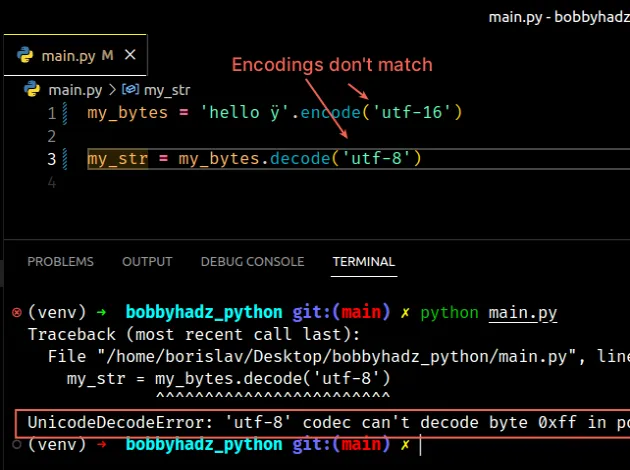
我们使用utf-16编码将字符串编码为字节,但随后尝试使用utf-8编码将字节对象解码为字符串。
编码不匹配会导致错误。
string编码是将 a 转换为对象的过程,解码是将对象转换为 a 的过程。 bytes bytesstring使用与将字符串编码为字节相同的编码
解码字节对象时,我们必须使用与将字符串编码为字节对象相同的编码。
在示例中,我们可以将编码设置为utf-16.
my_bytes = 'hello ÿ'.encode('utf-16') my_str = my_bytes.decode('utf-16') print(my_str) # 👉️ "hello ÿ"
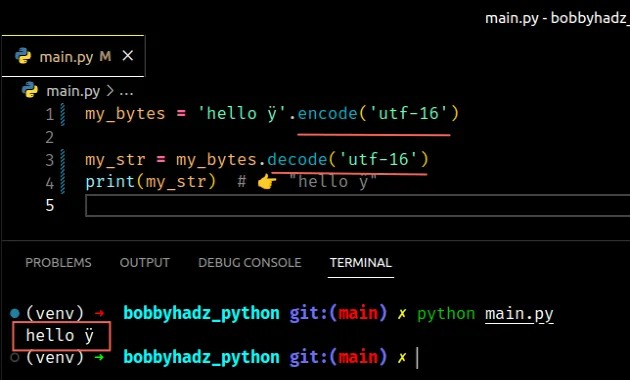
编码utf-16用于将字符串编码为字节,因此在解码字节对象时应使用它。
utf-16即使您不确定它是否用于对字符串进行编码,您也应该尝试使用该编码。
打开文件时指定正确的编码
您还可以在调用本机
open() 函数时设置编码。
with open('example.txt', 'r', encoding='utf-16') as f: lines = f.readlines() print(lines)
尝试将编码设置为utf-16代码示例中所示。
utf-16使用 pandas 时设置编码
如果您在使用pandas模块时遇到错误
,请
utf-16在对pandas.read_csv().
import pandas as pd df = pd.read_csv( 'employees.csv', sep=',', encoding='utf-16' ) print(df)
该read_csv方法采用用于设置编码的编码关键字参数。
将errors关键字参数设置为ignore
如果您不知道正确的编码,请尝试将
errors 关键字参数设置
为ignore。
my_bytes = 'hello ÿ'.encode('utf-16') my_str = my_bytes.decode('utf-8', errors='ignore') print(my_str) # hello
当errors关键字参数设置为忽略时,不会引发错误。
相反,无法解码的字符会从结果中删除。
需要注意的是,忽略无法解码的字符会导致数据丢失。
打开文件时设置errors关键字参数ignore
您可以在处理文件时使用相同的方法。
# 👇️ set errors to ignore with open('example.txt', 'r', encoding='utf-16', errors='ignore') as f: lines = f.readlines() print(lines)
我们将errors关键字参数设置为ignore,因此无法解码的字符将被忽略。
errors使用设置为的不正确编码打开文件ignore不会引发UnicodeDecodeError.
你可以在不解码的情况下以二进制模式打开文件
如果您在打开文件时遇到错误,您可以在不解码的情况下以二进制模式打开文件。
with open('example.txt', 'rb') as f: data = f.read() # b'first line\nsecond line\nthird line\n' print(data)
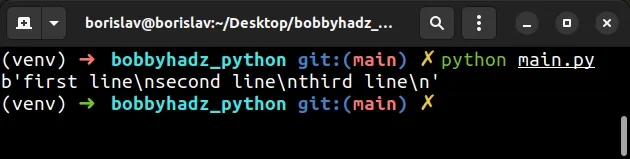
我们以二进制模式打开文件(使用rb(读取二进制)模式),因此
lines列表包含字节对象。
以二进制模式打开文件时不应
指定编码。
确保在以二进制模式打开文件时没有指定编码,否则会出现 ValueError
: binary mode doesn’t take an encoding argument
错误。
尝试将编码设置为ISO-8859-1
ISO-8859-1您可以尝试的另一件事是在解码字节对象或打开文件时将编码设置为。
my_bytes = 'hello ÿ'.encode('utf-16') my_str = my_bytes.decode('ISO-8859-1') print(my_str) # ÿþhello ÿ
当编码设置为ISO-8859-1时,您不会收到错误消息
,但是,您可能会收到难以辨认的结果。
编码ISO-8859-1为 256 个可能的字节值中的每一个定义一个字符,因此不会引发错误。
这是从文件读取时使用编码的示例。
with open('example.txt', 'r', encoding='ISO-8859-1') as f: lines = f.readlines() print(lines)
尝试用编码打开utf-16文件
如果这些建议都没有帮助,请尝试将编码设置为utf-16.
with open('example.txt', 'r', encoding='utf-16') as f: lines = f.readlines() print(lines)
试图找到文件的编码
您可以尝试使用命令来弄清楚文件的编码是什么file
。
该命令在 macOS 和 Linux 上可用,但如果安装了 git 和 Git Bash,也可以在 Windows 上使用。
如果在 Windows 上,请确保在 Git Bash 中运行该命令。
在包含该文件的目录中打开 shell,然后运行以下命令。
file *
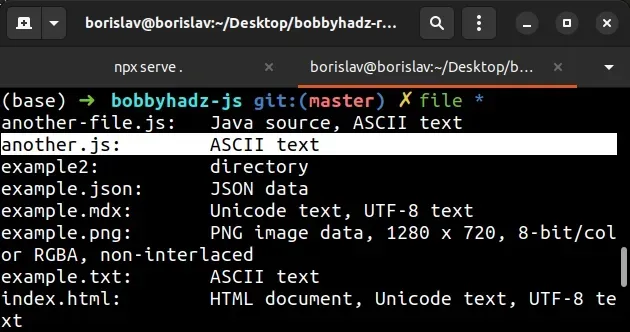
屏幕截图显示该文件使用ASCII编码。
这是您在打开文件时应指定的编码。
with open('example.txt', 'r', encoding='ascii') as f: lines = f.readlines() print(lines)
如果您使用的是 Windows,您还可以:
- 在记事本的基本版本中打开文件。
- 单击“另存为”。
- 查看“保存”按钮旁边的所选编码。
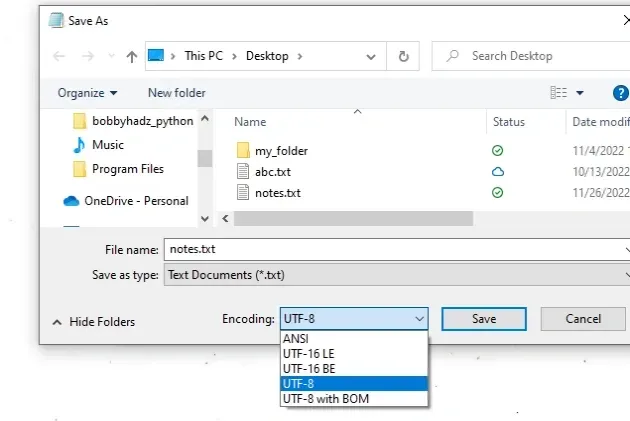
屏幕截图显示文件的编码是UTF-8,因此这是我们在调用函数时必须指定的open()。
如果指定不受支持的编码,则会出现
LookupError: unknown encoding in Python
错误。
查找文件的编码chardet
您还可以使用chardet Python 模块来尝试查找文件的编码。
首先,通过运行以下命令安装模块。
pip install chardet # 👇️ or pip3 pip3 install chardet
现在按如下方式运行chardetect命令。
chardetect example_file
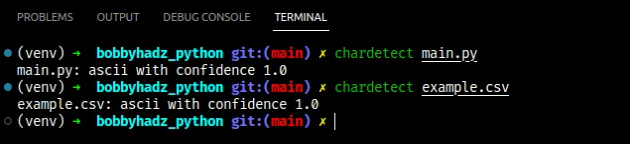
该包应该让您猜测文件使用了哪种编码,包括置信度分数。
然后您可以尝试在打开文件时使用编码。
with open('example.txt', 'r', encoding='your_encoding') as f: lines = f.readlines() print(lines)
您也可以尝试以二进制方式打开文件,并使用chardet包来检测文件的编码。
import chardet with open('example.txt', 'rb') as f: print(chardet.detect(f.read()))
我们使用rb(读取二进制)模式并将文件的输出提供给该
chardet.detect()方法。
您通过调用该方法获得的编码是您在以阅读模式打开文件时应该尝试的编码。
错误是如何产生的
string编码是将 a 转换为对象的过程,解码是将对象转换为 a 的bytes过程。bytesstring
解码字节对象时,我们必须使用与将字符串编码为字节对象相同的编码。
下面是一个示例,显示使用不同的编码将字符串编码为字节而不是用于解码字节对象的编码如何导致错误。
my_text = 'hello ÿ' my_binary_data = my_text.encode('utf-16') # ⛔️ UnicodeDecodeError: 'utf-8' codec can't decode byte 0xff in position 0: invalid start byte my_text_again = my_binary_data.decode('utf-8')
utf-16我们可以通过使用编码来解码字节对象来解决错误。
my_text = 'hello ÿ' my_binary_data = my_text.encode('utf-16') my_text_again = my_binary_data.decode('utf-16') print(my_text_again) # 👉️ "hello ÿ"