
UnicodeEncodeError: ‘ascii’ 编解码器无法对字符进行编码
UnicodeEncodeError: ‘ascii’ codec can’t encode character in position
ascii当我们使用编解码器对包含非 ascii 字符的字符串进行编码时,会出现 Python“UnicodeEncodeError: ‘ascii’ codec can’t encode character in position” 。
要解决该错误,请指定正确的编码,例如utf-8.

下面是错误如何发生的示例。
my_str = 'one ф' # ⛔️ UnicodeEncodeError: 'ascii' codec can't encode character '\u0444' in position 4: ordinal not in range(128) my_bytes = my_str.encode('ascii')
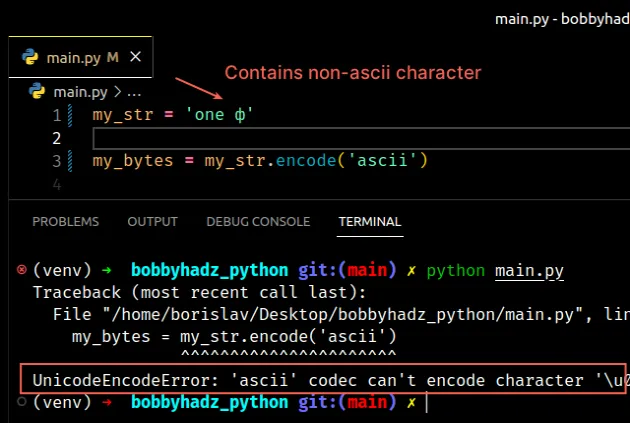
该错误是由于字符串中包含非ASCII 字符引起的。
使用正确的编码方式对字符串进行编码
要解决该错误,请使用正确的编码对字符串进行编码,例如utf-8.
my_str = 'one ф' my_bytes = my_str.encode('utf-8') print(my_bytes) # 👉️ b'one \xd1\x84'
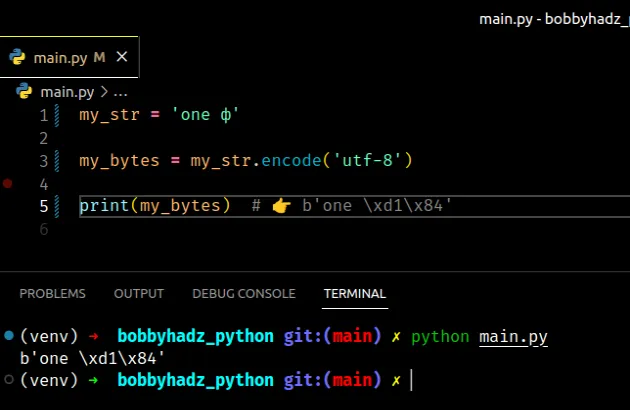
utf-8编码能够在 Unicode 中编码超过一百万个有效字符代码点。如果打开文件时出现错误,请
utf-8在调用
open() 函数时将编码关键字参数设置为。
my_str = 'one ф' # 👇️ set encoding to utf-8 with open('example.txt', 'w', encoding='utf-8') as f: f.write(my_str)
您可以在官方文档的此表中查看所有标准编码
。
string编码是将 a 转换为对象的过程,解码是将对象转换为 a 的过程。 bytes bytesstring这是完整的过程。
my_str = 'one ф' # 👇️ encode str to bytes my_bytes = my_str.encode('utf-8') print(my_bytes) # 👉️ b'one \xd1\x84' # 👇️ decode bytes to str my_str_again = my_bytes.decode('utf-8') print(my_str_again) # 👉️ "one ф"
解码字节对象时,我们必须使用与将字符串编码为字节对象相同的编码。
str.encode ()方法用于将字符串转换为字节。
该bytes.decode()方法用于将bytes对象转换为字符串。
确保不要将两者混用,因为这通常会导致问题。
将errors关键字参数设置为ignore
如果使用编码时错误仍然存在utf-8,请尝试将
错误关键字参数设置
为ignore忽略无法编码的字符。
my_str = 'one ф' # 👇️ encode str to bytes my_bytes = my_str.encode('utf-8', errors='ignore') print(my_bytes) # 👉️ b'one \xd1\x84' # 👇️ decode bytes to str my_str_again = my_bytes.decode('utf-8', errors='ignore') print(my_str_again) # 👉️ "one ф"
请注意,忽略无法编码的字符会导致数据丢失。
尝试使用ascii编码对字符串进行编码
您也可以尝试使用设置为的ascii编码来忽略任何非 ASCII 字符。errorsignore
my_str = 'one ф' # 👇️ encode str to bytes my_bytes = my_str.encode('ascii', errors='ignore') print(my_bytes) # 👉️ b'one ' # 👇️ decode bytes to str my_str_again = my_bytes.decode('ascii', errors='ignore') print(my_str_again) # 👉️ "one"
请注意,当我们将字符串编码为字节时,最后一个字符(非 ASCII 字符)被丢弃了。
打开文件时设置encoding关键字参数utf-8
如果打开文件时出现错误,请打开编码
设置
为utf-8.
my_str = 'one ф' # 👇️ set encoding to utf-8 with open('example.txt', 'w', encoding='utf-8') as f: f.write(my_str)
您还可以将errors关键字参数设置为ignore以在打开文件时忽略任何编码错误。
my_str = 'one ф' with open('example.txt', 'w', encoding='utf-8', errors='ignore') as f: f.write(my_str)
使用环境变量全局设置编码
如果错误仍然存在,请尝试使用环境变量全局设置编码。
# on Linux and macOS export PYTHONIOENCODING=utf-8 # on Windows setx PYTHONIOENCODING=utf-8 setx PYTHONLEGACYWINDOWSSTDIO=utf-8
确保根据您的操作系统使用正确的命令。
必须在运行脚本之前设置环境变量。
如果
在运行解释器之前设置了PYTHONIOENCODINGstdin环境变量,它将覆盖用于和 的
编码stdout。
在 Windows 上,您还必须设置
PYTHONLEGACYWINDOWSSTDIO
环境变量。
如果错误仍然存在,请尝试在文件顶部添加以下行。
import sys sys.stdin.reconfigure(encoding='utf-8') sys.stdout.reconfigure(encoding='utf-8')
如果没有其他方法,该sys模块可用于全局设置编码。
在尝试写入文件或将字符串编码为字节之前,请确保将 at 行添加到文件顶部。
发送邮件时设置encoding关键字参数utf-8
如果您在使用模块时遇到错误smtplib,请utf-8在发送之前使用编码对字符串进行编码。
my_str = 'one ф' encoded_message = my_str.encode('utf-8') server.sendmail( 'from@gmail.com', 'to@gmail.com', encoded_message )
请注意,我们将编码后的消息作为参数传递给server.sendmail().
如果您不自己对消息进行编码,Python 将在您调用该方法时尝试使用 ASCII 编解码器对其进行编码sendmail()。
由于消息包含非 ASCII 字符,因此会引发错误。
错误设置LANG和环境变量LC_ALL
如果您使用的是 Debian (Ubuntu),如果您错误地设置了以下 2 个环境变量,则可能会出现错误。
LANG– 在没有其他与语言环境相关的环境变量的情况下确定默认语言环境。LC_ALL– 覆盖所有语言环境变量(除了LANGUAGE)。
您可以使用命令打印环境变量echo。
echo $LANG echo $LC_ALL
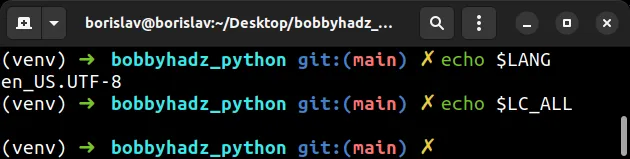
环境LANG变量应设置为en_US.UTF-8,LC_ALL
环境变量不应设置。
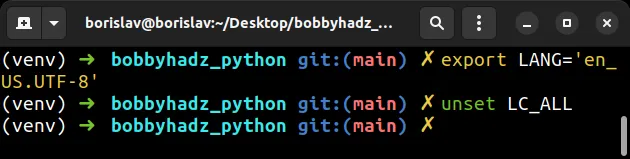
如果需要更正环境变量的值,可以运行以下命令。
# ✅ set LANG environment variable export LANG='en_US.UTF-8' # ✅ unset LC_ALL environment variable unset LC_ALL
如果错误仍然存在,请尝试language-pack-en从您的终端安装软件包。
sudo apt-get install language-pack-en
如果您的操作系统已过时并且缺少依赖项,这可能会有所帮助。